Programming, graphics, games, media, C++, Windows, Internet and more...
Entries for tag ".net", ordered from most recent. Entry count: 20.
# The Beauty of Sorted Arrays
Sat
20
Mar 2010
A one-dimmensional array (also called vector) is very simple data structure. We were taught that inserting or deleting elements in the middle of the array is slow because we have to move (by rewriting) all following elements. That's why books about C++ teach that for sorted collections - those who provide fast search operation - it's better to use containers like std::set or std::map.
But those who code games in C++ and care about performance know that today's processors (CPU) are very fast in terms of doing calculations and processing lots of data, while access to the RAM memory becomes more and more kind of a bottleneck. According to great presentation Pitfalls of Object Oriented Programming by Tony Albrecht from Sony, a cachce miss (access to some data from the memory which are not currently in CPU cache) costs about 400 cycles! Dynamic memory allocation (like operator new in C++) is also a slow operation. That's why data structures that use separate nodes linked with pointers (like std::list, std::set, std::map) are slower than std::vector and it's often better to keep a sorted collection of elements in a vector, even if you have hundreds or thousands of elements and must sometimes insert or delete them from the middle.
Unfortunately, C++ STL doesn't provide a "std::ordered_vector" container that whould keep items sorted while allocating single chunk of continuous memory. We have to do it by ourselves, like this:
First, we have to choose a way to compare elements. There are multiple solutions (read about comparators in C++), but the simplest one is to just overload operator < in your element structure.
#include <vector>
#include <string>
#include <algorithm>
struct Item
{
int Id;
DWORD Color;
std::string Name;
Item() { }
Item(int id, DWORD color, const std::string name)
: Id(id), Color(color), Name(name) { }
bool operator < (const Item &rhs) const { return Id < rhs.Id; }
};
typedef std::vector<Item> ItemVector;
ItemVector vec;
Item item;
Here is how we insert an item into sorted vector:
item = Item(1, 0xFF0000, "Red"); ItemVector::iterator itToInsert = std::lower_bound( vec.begin(), vec.end(), item); vec.insert(itToInsert, item);
Unfortunately we have to deal with iterators instead of simple indices.
To check if the vector contains element with particular Id:
item = Item(1, 0, std::string()); bool contains = std::binary_search(vec.begin(), vec.end(), item);
Here come another nuisances. We have to create full Item object just to use its Id field for comparison purpose. I'll show tomorrow how to overcome this problem.
It's also annoying that binary_search algorithm returns bool instead of iterator that would show us where the found item is. To find an item and determine its iterator (and from this its index) we have to use lower_bound algorithm. This algorithm is very universal but also hard to understand. It quickly searches a sorted collection and returns the position of the first element that has a value greater than or equivalent to a specified value. It was perfect for determining a place to insert new item into, but to find existing element, we have to use it with this if:
item = Item(1, 0, std::string());
ItemVector::iterator findIt = std::lower_bound(vec.begin(), vec.end(), item);
if (findIt != vec.end() && findIt->Id == item.Id)
{
size_t foundIndex = std::distance(vec.begin(), findIt);
}
else
{
// Not found.
}
And finally, to remove an item from the vector while having index, we do this trick:
size_t indexToDelete = 0; vec.erase(vec.begin() + indexToDelete);
Well, C++ STL is very general, universal, powerful and... very complicated, while standard libraries of other programming languages also have some curiosities in their array classes.
For example, ActionScript 3 have single method to insert and remove items:
function splice(startIndex:int, deleteCount:uint, ... values):Array
To delete some items, you pass non-zero deleteCount. To insert some items, you pass them as values parameter.
In .NET, the System.Collections.Generic.List<T> class (which is actually an array, the name is misnomer) has very smart BinarySearch method. It returns the "zero-based index of item (...), if item is found; otherwise, a negative number that is the bitwise complement of the index of the next element that is larger than item or, if there is no larger element, the bitwise complement of Count.". It can be used to both find existing item in the array or determine an index for a new item, like:
int index = myList->BinarySearch("abc");
if (index < 0)
myList->Insert(~index, "abc");
See also: My Algorithms for Sorted Arrays
Comments | #algorithms #c++ #stl #.net #flash Share
# How to Disable Redrawing of a Control
Thu
18
Mar 2010
When coding Windows application with GUI, there is an issue about how long does it take to add lots of items (like hundreds or thousands) into a list view or tree view control. It is caused by redrawing the control after each operation. I've seen this annoying effect in may programs, including some serious, commercial ones. Apparently many programmers don't know there is a simple solution. But first a bit of background...
When coding games, we constantly spin inside a big loop and redraw whole screen every frame. Calculations are separated from rendering so we can, for example, build a list with thousands of items in the computation function and the visible part of the list will start being rendered since the first rendering function call after that. When coding windowed applications, nothing new is drawn onto the screen unless needed. We have to manually do it and we can call redrawing function any time. So how should a list control be refreshed when we add an item into it? It is done automatically after each insert, which is a good solution... unless we want to add hundreds of them.
So GUI library developers provide a functionality to temporarily disable redrawing of a control.
Comments | #.net #mfc #wxwidgets #winapi #gui Share
# The Concept of Immutability and Descriptor
Fri
27
Nov 2009
An object of some class represents a piece of data, chunk of memory or other resource along with methods to operate on it. It should also automatically free these resources in destructor. But how should modifying these data look like? There are two possible approaches. As an example, let's consider a fictional class to encapsulate Direct3D 9 Vertex Declaration (I'll show my real one in some future blog entry). A Vertex Declaration is an array of D3DVERTEXELEMENT9 structures, which can be used to create IDirect3DVertexDeclaration9 object. First solution is to define class interface in a way that data inside can be modified at any time.
class MyMutableVertexDecl
{
public:
// Creates an empty declaration.
MyMutableVertexDecl();
// Frees all allocated resources.
~MyMutableVertexDecl();
// Copies data from another object
void CopyFrom(const MyMutableVertexDecl &src);
// Deletes all internal data so object becomes empty again.
void Clear();
bool IsEmpty() const;
// I/O (Serialization)
void SaveToStream(IStream &s) const;
void LoadFromStream(IStream &s);
// Reading of underlying data
size_t GetElemCount() const;
const D3DVERTEXELEMENT9 & GetElem(size_t index) const;
// Modification of underlying array
void SetElem(const D3DVERTEXELEMENT9 &elem, size_t index);
void AddElem(const D3DVERTEXELEMENT9 &elem);
void InsertElem(const D3DVERTEXELEMENT9 &elem, size_t index);
void RemoveElem(size_t index);
IDirect3DVertexDeclaration9 * GetD3dDecl() const;
private:
std::vector<D3DVERTEXELEMENT9> m_Elems;
IDirect3DVertexDeclaration9 *m_D3dDecl;
...
};
This approach seems very nice as you can create your object any time you wish and fill it with data later, as well as change this data whenever you need to. But at the same time, a question emerges: when to (re)create "destination" IDirect3DVertexDeclaration9 from the "source" D3DVERTEXELEMENT9 array? Each time the array is modified? Or maybe each time the IDirect3DVertexDeclaration9 is retrieved? Optimal solution for the interface above would be to do lazy evaluation, that is to recreate IDirect3DVertexDeclaration9 whenever it is retrieved for the first time since last time the D3DVERTEXELEMENT9 array have been modified. But...
Comments | #software engineering #directx #.net #physics #c++ Share
# What is C++/CLI ?
Fri
25
Sep 2009
Today I've started learning C++/CLI. It's a Microsoft technology that allows to write managed code for .NET platform in C++. But I can see it's not just a Microsoft idea to introduce custom language extensions. It's a massive piece of technology and even some C++ gurus were involved in its development, like Herb Sutter and Stanley Lippman. It's also approved as ECMA-372 standard.
So what exactly is C++/CLI? It's yet another language for .NET, just like C# or VB.NET, but it has the unique feature of being compatible with native C++ and being able to freely mix managed and unmanaged code.
For many people it may trigger some bad connotations with ugly syntax like __gc, __interface, __property etc., but that's not true. Syntax like this existed in Managed Extensions for C++, but C++/CLI is its new, improved version introduced in Visual Studio 2005.
Here is a screenshot from my first experiment, where I've created a property grid control from .NET next to a native Direct3D9 device initialized inside a panel control.

Just look at how old good native code can be mixed with managed one:
#include <d3dx9.h>
namespace ManagedCpp02 {
using namespace System::Windows::Forms;
...
public:
Form1()
{
PropertyGrid^ propertyGrid1 = gcnew PropertyGrid();
...
IDirect3D9 *d3d = Direct3DCreate9(D3D_SDK_VERSION);
System::Diagnostics::Debug::Assert(d3d != nullptr);
Microsoft wasn't afraid to introduce new keywords and operators to the language. These designed to operate on managed code work next to the native ones, so you can define and use native and managed classes next to each other just like this:
class NativeClass { };
// Allocate from unmanaged heap - memory must be freed.
NativeClass *nPtr = new NativeClass();
delete nPtr;
ref class ManagedClass { };
// Allocate from managed heap - garbage collected.
ManagedClass ^mPtr = gcnew ManagedClass();
Comments | #c++ #.net #visual studio Share
# Professional Developers Conference 2008
Wed
17
Dec 2008
PDC - Professional Developers Conference to konferencja firmy Microsoft. Dla niektórych to nie nowość, bo tegoroczna edycja odbyła się 27-30 października 2008, ale ja dziś właśnie przeglądałem sobie prezentacje z tego wydarzenia, dostępne na stronie PDC 2008 / Agenda / Sessions. Jest tam w sumie 207 sesji, z których do większości można pobrać prezentację PPTX. Wykłady dotyczą głównie "biznesowo-bazodanowych" technologii Microsoftu, jak .NET, SQL Server, ADO, ASP itp.
Ci którzy kodują w bardziej tradycyjnych technologiach też mogą jednak znaleźć tam ciekawe rzeczy. Moją uwagę zwróciły m.in. informacje na temat co nowego pojawi się w kolejnych wersjach produktów firmy, jak .NET Framework 4.0 czy Visual Studio 10. Widać, że Microsoft żywiołowo idzie do przodu i rozwija swoje oprogramowanie zgodnie z nowoczesnymi trendami. Pojawią się fajne narzędzia, biblioteki oraz rozszerzenia języków programowania (C++, C#) wspierające programowanie równoległe. C# stanie się bardziej dynamiczny. Samo IDE natomiast otrzyma nowe możliwości, m.in. będzie mogło wyświetlać minimapkę z kodu, taką o jakiej zawsze marzyłem i jaką opisałem kiedyś wśród swoich pomysłów :)

Comments | #visual studio #.net #c++ #windows #events #gui Share
# Przewijanie konsoli
Sun
23
Nov 2008
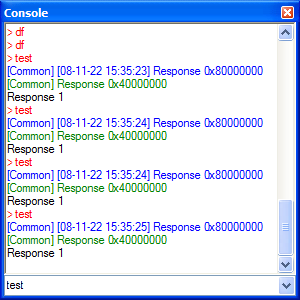
Kiedy piszemy konsolę w postaci zwykłego systemowego okienka z kontrolką RichEdit, powstaje pytanie, czy podczas dodawania nowego komunikatu przewijać ją na dół. Jeśli nie, to będzie denerwujące dla użytkownika, który chciałby stale widzieć najnowsze komunikaty. Jeśli tak, to będzie denerwujące dla tego, kto chciałby przeczytać konkretny komunikat mimo pojawiania się nowych. Co więc zrobić? Przycisk, który pozwoli zablokować przewijanie konsoli?
Moim zdaniem najlepiej jest zrobić tak, jak to robi Visual C++ choćby w okienku Output - przewijać, jeśli kursor jest na końcu i nie przewijać, jeśli użytkownik umieści go gdzieś wyżej. W C# z kontrolką typu RichTextBox można to zrobić tak:
public void OutputLine(string Text, Color c) {
int SelectionStart = RichTextBox1.SelectionStart;
bool SelectionAtEnd =
(SelectionStart == RichTextBox1.Text.Length) &&
(RichTextBox1.SelectionLength == 0);
RichTextBox1.SelectionStart = RichTextBox1.Text.Length;
RichTextBox1.SelectionLength = 0;
RichTextBox1.SelectionColor = c;
RichTextBox1.AppendText(Text + "\r\n");
if (SelectionAtEnd)
RichTextBox1.ScrollToCaret();
else
RichTextBox1.SelectionStart = SelectionStart;
}
# Ścieżka do Application Data w C#
Thu
17
Apr 2008
Żeby program był elegancki i działał dobrze (zwłaszcza pod Vista...), powinien swoje pliki konfiguracyjne i inne dane trzymać w katalogu C:\Dokuments and Settings\Login\Application Data\..., a nie w podkatalogu Program Files, gdzie leży plik wykonywalny. Jak pobrać ścieżkę do tego katalogu w C#?
Microsoft przewidział do tego metodę statyczną Application.UserAppDataPath. Niestety ona działa w ten sposób, że zwraca (a jeśli nie istnieje to także tworzy na dysku) ścieżkę typu Application Data\Nazwa firmy\Nazwa programu\Wersja.Wersja.Wersja.Wersja. Taka zamotana ścieżka to nienajlepszy pomysł. Szczególnie, że konfiguracja powinna działać także w nowych wersjach programu.
Dlatego lepszym rozwiązaniem jest chyba taki kod:
private string GetConfigFileName()
{
string Dir = System.IO.Path.Combine(
Environment.GetFolderPath(
Environment.SpecialFolder.ApplicationData),
"Nazwa programu");
if (!System.IO.Directory.Exists(Dir))
System.IO.Directory.CreateDirectory(Dir);
return System.IO.Path.Combine(Dir, "Plik.ext");
}
# Konwersja między liczbą a łańcuchem w C# - z kropką
Sun
27
Jan 2008
C# to piękny język, ale ostatnio natrafiłem na mały problem. Podczas konwersji liczby typu float na łańcuch typu string i odwrotnie, jako symbol dziesiętny domyślnie używany jest polski przecinek zamiast powszechnie przyjętej na świecie kropki. To jest problem, bo co jeśli na przykład tekstowy plik konfiguracyjny dołącozny do programu zawiera liczbę rzeczywistą zapisaną z kropką, a na komputerach użytkowników w zależności od ustawień międzynarodowych funkcja do konwersji będzie szukała przecinka czy jeszcze innego znaku?
Winne temu są oczywiście ustawienia kraju/języka (zwane w .NET "culture", w C/C++ "locale"). W C i C++ można spotkać to samo zjawisko, ale tam w programach trzeba to "locale" ręcznie ustawić posługując się funkcją setlocale czy też klasą locale z nagłówka <locale>. Domyślnie aktywne jest ustawienie angielskie. Aby w C# dokonać prawidłowej konwersji, trzeba zrobić tak:
1. Utworzyć obiekt klasy CultureInfo. Dla nas ważne jest, że on implementuje interfejs IFormatProvider. Przekazany do konstruktora łańcuch pusty oznacza "Invariant culture", a w praktyce obyczaje tekstowe dla języka angielskiego.
IFormatProvider FormatProvider =
new System.Globalization.CultureInfo("");
2. Konwersja łańcucha na liczbę typu float z użyciem tego obiektu może wyglądać tak:
bool Result = float.TryParse( MyString, System.Globalization.NumberStyles.Float | System.Globalization.NumberStyles.AllowThousands, FormatProvider, out MyFloat);
3. Przykładowa konwersja liczby na łańcuch wygląda natomiast tak:
StringBuilder SB = new StringBuilder();
SB.AppendFormat(FormatProvider, "Number={0}", MyFloat);